
La théorie des probabilités
Saviez-vous ...
SOS croit que l'éducation donne une meilleure chance dans la vie des enfants dans le monde en développement aussi. Avec enfants SOS vous pouvez choisir de parrainer des enfants dans plus de cent pays
La théorie des probabilités est la branche de mathématiques concernés par l'analyse des phénomènes aléatoires. Les objets centraux de la théorie des probabilités sont variables aléatoires , processus stochastiques et événements: abstractions mathématiques événements non déterministes ou les quantités mesurées qui peuvent être soit occurrences uniques ou évoluer au fil du temps de façon apparemment aléatoire. Bien qu'une pièce individuelle jeter ou le rouleau d'un dé est un événement aléatoire, se il est répété de nombreuses fois la séquence des événements aléatoires présente certaines tendances statistiques, qui peuvent être étudiés et prévisibles. Deux résultats mathématiques représentatifs décrivant ces modèles sont les loi des grands nombres et le théorème central limite.
En tant que fondation mathématique pour les statistiques , la théorie des probabilités est essentielle pour de nombreuses activités humaines qui impliquent l'analyse quantitative de grands ensembles de données. Méthodes de la théorie des probabilités se appliquent également à la description des systèmes complexes donnés qu'une connaissance partielle de leur état, comme dans la mécanique statistique . Une grande découverte de XXe siècle la physique était la nature probabiliste des phénomènes physiques à des échelles atomiques, décrites dans la mécanique quantique .
Histoire
La théorie mathématique de probabilité a ses racines dans les tentatives pour analyser jeux de hasard par Jérôme Cardan au XVIe siècle, et par Pierre de Fermat et Blaise Pascal au XVIIe siècle (par exemple le " problème de points ").
Initialement, la théorie des probabilités principalement considéré événements discrets, et ses méthodes étaient essentiellement combinatoire . Finalement, analytiques considérations ont amené l'intégration de variables continues dans la théorie. Ce abouti à la théorie moderne des probabilités, les fondations de ce qui ont été portées par Andrey Nikolaevich Kolmogorov. Kolmogorov associé la notion de l'espace échantillon, introduit par Richard von Mises, et théorie de la mesure et a présenté ses système d'axiomes de la théorie des probabilités en 1933. Assez rapidement ce est devenu le leader incontesté base axiomatique de la théorie moderne des probabilités.
Traitement
La plupart des introductions à la théorie des probabilités traitent des distributions de probabilités discrètes et les distributions de probabilités continues séparément. Le traitement plus mathématiquement avancé basé théorie de la mesure de la probabilité couvre à la fois discret, continu, ne importe quel mélange de ces deux et plus encore.
Distributions de probabilité discrètes
La théorie des probabilités discrète traite avec des événements qui se produisent dans espaces d'échantillons dénombrables.
Exemples: Lancer des dés , des expériences avec jeux de cartes , et marche aléatoire.
Définition classique: Initialement, la probabilité d'un événement de se produire a été définie comme le nombre de cas favorables pour l'événement, sur le nombre de résultats possibles au total dans un espace de l'échantillon équiprobable.
Par exemple, si l'événement est "apparition d'un nombre pair quand une matrice est roulé », la probabilité est donnée par  , Depuis trois faces sur 6 ont nombres pairs et chaque face a la même probabilité d'apparaître.
, Depuis trois faces sur 6 ont nombres pairs et chaque face a la même probabilité d'apparaître.
Définition moderne: la définition moderne commence avec un jeu appelé l'espace de l'échantillon, qui se rapporte à l'ensemble de tous les résultats possibles en sens classique, notée  . On suppose alors que pour chaque élément
. On suppose alors que pour chaque élément 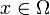 , Une valeur intrinsèque "de probabilité"
, Une valeur intrinsèque "de probabilité"  est fixé, ce qui satisfait les propriétés suivantes:
est fixé, ce qui satisfait les propriétés suivantes:
![f (x) \ in [0,1] \ mbox {} pour tous les x \ in \ Omega \ ,;](../../images/493/49335.png)
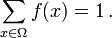
Autrement dit, la fonction de probabilité f (x) se situe entre zéro et un pour chaque valeur de x dans la Ω spatiale de l'échantillon et la somme de f (x) sur toutes les valeurs x dans le Ω d'espace d'échantillon est exactement égale à 1. événement est défini comme tout sous-ensemble  de l'espace d'échantillon
de l'espace d'échantillon  . La probabilité de l'événement défini comme
. La probabilité de l'événement défini comme

Ainsi, la probabilité de l'espace d'échantillon entier est 1, et la probabilité de l'événement nulle est 0.
La fonction mappage d'un point dans l'espace d'échantillon à la valeur de "probabilité" est appelée Fonction de masse abrégé en pmf. La définition moderne ne cherche pas à répondre à la façon dont les fonctions de masse de probabilité sont obtenus; se appuie au contraire une théorie qui suppose leur existence.
Distributions de probabilités continues
La théorie de la probabilité continue traite avec des événements qui se produisent dans un espace de l'échantillon continue.
Définition classique: La définition classique se décompose lorsqu'il est confronté à l'affaire continue. Voir Le paradoxe de Bertrand.
Définition moderne: Si l'espace de l'échantillon est les nombres réels (  ), Alors une fonction appelée fonction de répartition (ou cdf)
), Alors une fonction appelée fonction de répartition (ou cdf) 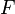 est supposé exister, ce qui donne
est supposé exister, ce qui donne  pour une variable aléatoire X. Ce est, F (x) renvoie la probabilité que X sera inférieur ou égal à x.
pour une variable aléatoire X. Ce est, F (x) renvoie la probabilité que X sera inférieur ou égal à x.
Le CDF doit satisfaire les propriétés suivantes.
- est un monotone non décroissante, fonction continue à droite;
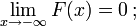

Si est différentiables, alors la variable aléatoire X est dit d'avoir un fonction de densité de probabilité ou pdf ou simplement densité 
Pour un ensemble 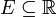 , La probabilité de la variable aléatoire X étant est défini comme étant
, La probabilité de la variable aléatoire X étant est défini comme étant
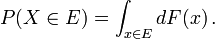
Dans le cas où la fonction de densité de probabilité existe, ce qui peut se écrire

Alors que le pdf ne existe que pour les variables aléatoires continues, la fonction de répartition existe pour toutes les variables aléatoires (y compris les variables aléatoires discrètes) qui prennent des valeurs sur 
Ces concepts peuvent être généralisés pour cas multidimensionnels sur 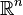 et autres espaces d'échantillons en continu.
et autres espaces d'échantillons en continu.
La théorie des probabilités Mesurer la théorie
La raison d'être du traitement de la probabilité mesure la théorie est qu'il unifie le discret et continu, et fait la différence une question de mesure utilisée. De plus, elle couvre les distributions qui ne sont ni des mélanges discrets continus ni ni des deux.
Un exemple d'une telle distribution peut être un mélange de distributions discrètes et continues, par exemple, une variable aléatoire qui est égal à 0 avec une probabilité de 1/2, et prend une valeur de distribution normale aléatoire avec une probabilité de 1/2. Il peut encore être étudié dans une certaine mesure en le considérant d'avoir un pdf ![(\ Delta [x] + \ varphi (x)) / 2](../../images/493/49348.png) Où
Où ![\ Delta [x]](../../images/493/49349.png) est le Fonction delta Kronecker.
est le Fonction delta Kronecker.
Autres distributions peuvent même ne pas être un mélange, par exemple, le Loi de Cantor a aucune probabilité positive pour un point unique, ni ne ont une densité. L'approche moderne de la théorie des probabilités permet de résoudre ces problèmes en utilisant théorie de la mesure de définir l' espace de probabilité :
Compte tenu de tout ensemble  , (Également appelé l'espace de l'échantillon) et un σ-algèbre
, (Également appelé l'espace de l'échantillon) et un σ-algèbre  sur elle, un mesurer
sur elle, un mesurer 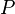 est appelé une mesure de probabilité si
est appelé une mesure de probabilité si
 est non négatif;
est non négatif; 
Si est un -Algèbre de Borel puis il ya une mesure de probabilité unique sur pour toute cdf, et vice versa. La mesure correspondant à une fonction de répartition est dit être induite par le CDF. Cette mesure coïncide avec le PMF pour les variables discrètes, et pdf pour les variables continues, ce qui rend l'approche de mesure théorie sans illusions.
La probabilité d'un ensemble dans la σ-algèbre est défini comme étant

où l'intégration est par rapport à la mesure  induite par
induite par 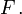
En plus de fournir une meilleure compréhension et à l'unification des probabilités discrètes et continues, le traitement de mesure théorie nous permet également de travailler sur des probabilités extérieur , Comme dans la théorie de processus stochastiques. Par exemple, pour étudier Mouvement brownien, la probabilité est définie sur un espace de fonctions.
Les distributions de probabilités
Certaines variables aléatoires se produisent très souvent dans la théorie des probabilités parce qu'ils décrivent ainsi de nombreux processus naturels ou physiques. Leurs distributions ont donc pris une importance particulière dans la théorie des probabilités. Certaines distributions discrètes fondamentales sont uniforme discrète, Bernoulli, binomiale , binomiale négative, Poisson et distributions géométriques. Distributions continues importants comprennent le continue et uniforme, normale , exponentielle , gamma et distributions bêta.
Convergence des variables aléatoires
Dans la théorie des probabilités, il ya plusieurs notions de convergence pour des variables aléatoires . Ils sont énumérés ci-dessous dans l'ordre de la force, ce est à dire, toute notion de convergence ultérieure dans la liste implique la convergence selon toutes les notions précédentes.
- Convergence dans la distribution: Comme son nom l'indique, une séquence de variables aléatoires
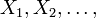 converge vers la variable aléatoire
converge vers la variable aléatoire 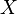 dans la distribution si leurs fonctions de répartition respectives
dans la distribution si leurs fonctions de répartition respectives 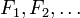 converger vers la fonction de distribution cumulative de , Où est continue.
converger vers la fonction de distribution cumulative de , Où est continue.
- La plupart notation commune de main courte:

- La plupart notation commune de main courte:
- Convergence faible: La séquence de variables aléatoires
 est dit à converger vers la variable aléatoire si faiblement
est dit à converger vers la variable aléatoire si faiblement 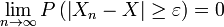 pour chaque ε> 0. Convergence faible est aussi appelé la convergence en probabilité.
pour chaque ε> 0. Convergence faible est aussi appelé la convergence en probabilité.
- La plupart notation commune de main courte:

- La plupart notation commune de main courte:
- Forte convergence: La séquence de variables aléatoires est dit à converger vers la variable aléatoire si fortement
 . Forte convergence est également connu comme convergence presque sûre.
. Forte convergence est également connu comme convergence presque sûre.
- La plupart notation commune de main courte:
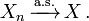
- La plupart notation commune de main courte:
Intuitivement, une forte convergence est une version plus puissante de la convergence faible, et dans les deux cas, les variables aléatoires montrent une corrélation croissante avec . Cependant, en cas de convergence dans la distribution, les valeurs réalisées des variables aléatoires ne ont pas à converger, et une corrélation possible entre eux est sans importance.
Loi des grands nombres
Intuition commune suggère que si une pièce de monnaie est lancée à plusieurs reprises, puis à peu près la moitié du temps il va tourner des têtes, et l'autre moitié, il se retrouvera queues. En outre, plus souvent le pièce est lancée, plus il devrait être que le rapport du nombre de têtes au nombre de queues se approchera unité. Probabilité moderne fournit une version officielle de cette idée intuitive, connu comme la loi des grands nombres. Cette loi est remarquable parce qu'il ne est nulle part supposé dans les fondements de la théorie des probabilités, mais émerge place sur ces fondations comme un théorème. Depuis il relie probabilités dérivées théoriquement à leur fréquence réelle dans le monde réel, la loi des grands nombres est considéré comme un pilier de l'histoire de la théorie statistique.
La loi des grands nombres (LLN) indique que la moyenne de l'échantillon  de (Indépendants et identiquement distribués variables aléatoires attente finie
de (Indépendants et identiquement distribués variables aléatoires attente finie  ) Converge vers l'attente théorique
) Converge vers l'attente théorique 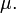
Ce est dans les différentes formes de convergence des variables aléatoires qui sépare le faible et le fort loi des grands nombres

Il résulte de LLN que si un événement de probabilité p est observé à plusieurs reprises au cours d'expériences indépendantes, le rapport de la fréquence observée de cet événement au nombre total de répétitions converge vers p.
Mettre cela en termes de variables aléatoires et nous avons LLN  sont indépendants Variables aléatoires de Bernoulli prenant des valeurs avec une probabilité p et 0 avec une probabilité 1- p.
sont indépendants Variables aléatoires de Bernoulli prenant des valeurs avec une probabilité p et 0 avec une probabilité 1- p. 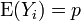 pour tout i et il se ensuit que de LLN
pour tout i et il se ensuit que de LLN 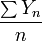 converge vers p presque sûrement.
converge vers p presque sûrement.
Théorème central limite
Le théorème central limite explique l'omniprésence de la distribution normale dans la nature; il est l'un des plus célèbres théorèmes en probabilités et statistiques.
Le théorème affirme que la moyenne de nombreuses variables aléatoires indépendantes et identiquement distribuées avec variance finie tend vers une distribution normale , indépendamment de la répartition suivie par les variables aléatoires originaux. Formellement, soit être des variables aléatoires indépendantes de moyenne 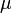 et variance
et variance 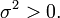 Ensuite, la séquence de variables aléatoires
Ensuite, la séquence de variables aléatoires
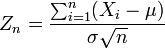
converge en distribution à une normale standard variable aléatoire.